Wann ist klassisches Computer Vision Deep Learning überlegen?
Hinweis zum Alter dieses Beitrags: Die Entwicklung bei KI im Allgemeinen und bei der LoyJoy Platform im Speziellen schreitet rasant voran. Die Informationen dieses Blog-Posts sind möglicherweise nicht mehr auf dem neuesten Stand.

Wir alle haben großartige Geschichten darüber gesehen, was mit Deep Learning (DL) möglich ist. Es ermöglicht Autos, selbst zu fahren, bestimmt die beste Behandlung für Patienten und kann auch dein Gesicht in jeden gewünschten Videoclip einfügen.
Aufgrund der vielen Erfolge mit DL erscheint es nur natürlich, es auf jedes Problem anzuwenden, das du lösen möchtest. Hüte dich vor dieser Voreingenommenheit: Die Verwendung von DL für Probleme, die mit weniger komplexen Methoden gelöst werden könnten, verursacht zusätzlichen Arbeits- und Kostenaufwand, den du besser vermeiden solltest.
In diesem Beitrag zeige ich dir genau, was die Vor- und Nachteile von DL sind und wann es am besten ist, es komplett zu vermeiden. Nutzer, die mit DL vertraut sind, können zum Abschnitt Nachteile von DL springen, um direkt zu meinen Argumenten zu kommen.
Was ist Deep Learning?
Um die (Nach-)Teile von DL zu verstehen, ist es wichtig, zunächst ein allgemeines Verständnis des Prozesses zu gewinnen. Einfach ausgedrückt, beschreibt DL einen Prozess, bei dem ein mathematisches Modell lernt, ein gewünschtes Ergebnis bei großen Mengen an Trainingsdaten zu produzieren.
Das mathematische Modell ist in diesem Fall ein mehrschichtiges neuronales Netzwerk, das oft Convolutional- und Max-Pool-Schichten enthält. In der Praxis kannst du dir das neuronale Netzwerk als viele miteinander verbundene logistische Regressionen vorstellen.
Eine logistische Regression ist eine Funktion, die Elemente anhand bestimmter Messungen kategorisiert. Logistische Regressionen können verwendet werden, um festzustellen, ob eine Gewebeprobe krebsartig ist oder nicht, z.B. basierend auf Zellgröße, Zellformen und anderen Messungen. Diese Messungen müssen in numerische Daten codiert werden, um in der logistischen Regression verarbeitet zu werden.
Ähnlich kann ein DL-Modell basierend auf den Bilddaten (Pixeln) bestimmen, ob ein Bild eine Katze enthält oder nicht. Um dies möglich zu machen, werden die rohen Pixel in den mehreren Schichten transformiert (z.B. durch Konvolution). Du kannst dir vorstellen, dass diese Schichten mehrere Tests enthalten: Enthält das Bild Augen, Ohren, Schnurrhaare: Alle Merkmale, die wir mit Katzen assoziieren würden (siehe diesen Blogbeitrag für eine großartige Visualisierung).
Deep Learning benötigt viele Trainingsdaten
Um zu lernen, welche Tests es verwenden sollte, werden dem DL-Modell viele verschiedene Bilder (die Trainingsdaten) präsentiert. Zunächst sind zufällige Tests im Modell enthalten und mit jedem Trainingsschritt werden die Tests so geändert, dass die endgültige Entscheidung genauer wird (dieser Prozess wird Backpropagation genannt).
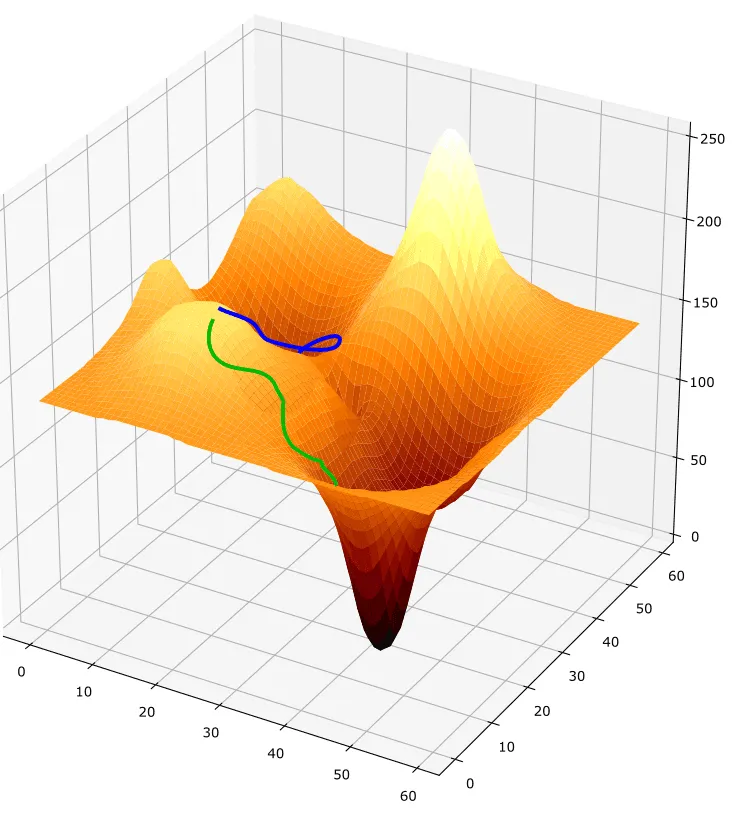
Beispiel für zwei Gradient-Descent-Durchläufe. Der erfolgreiche Durchlauf, der das globale Optimum erreicht, ist in Grün dargestellt. Der erfolglose Durchlauf, der in einem lokalen Minimum stecken bleibt, ist in Blau dargestellt.
Hier kommen wir zum ersten Problem von DL: Du benötigst viele Trainingsdaten. Im Fall von Katzenbildern kann dies relativ einfach zu erhalten sein, aber in anderen Fällen kann dies ziemlich schwierig sein. Außerdem müssen die Trainingsdaten beschriftet werden, was eine zusätzliche Herausforderung darstellen kann.
Zusätzlich zum Problem der Beschaffung von Trainingsdaten gibt es auch viele Qualitätsanforderungen an die Trainingsdaten. Die Trainingsdaten sollten den Daten, auf denen das Modell verwendet wird, so ähnlich wie möglich sein. Außerdem sollten keine Artefakte in den Trainingsdaten enthalten sein. Wenn beispielsweise alle Bilder mit Katzen ein bestimmtes Wasserzeichen enthalten, wird das Modell wahrscheinlich nur lernen, Katzenbilder anhand des Wasserzeichens zu unterscheiden.
Training kann zeitaufwändig sein - Ergebnisse sind nicht garantiert
Der eigentliche “Lern”-Prozess von DL ist das, was ich gerade als das Zeigen vieler Trainingsbilder an das Modell und das Anpassen seiner “Tests” beschrieben habe, um eine genauere Vorhersage zu treffen. Mathematisch werden diese Prozesse Backtracking (verwendet vom Modell, um herauszufinden, wo und wie die Tests falsch sind) und Gradient Descent (verwendet vom Modell, um zu bestimmen, wie die Tests geändert werden, um bessere Vorhersagen zu treffen) genannt.
Du kannst dir Gradient Descent so vorstellen, als würdest du auf einem Berg beginnen (viele Fehler machen) und versuchen, hinunterzugehen. Das Modell kann nur einige Meter auf einmal vorausschauen (indem es einen Bruchteil der Trainingsdaten betrachtet). Also überprüft das Modell, in welche Richtung die Steigung nach unten geht, und beginnt einfach zu “gehen”, wobei es nach jedem Schritt neu überprüft. Wenn jede Richtung von der Position des Modells nach oben geneigt ist, hat das Modell sein Ziel erreicht: Es hat ein Tal gefunden.
Jetzt kommt das eigentliche Problem: Du kannst nicht sicher sein, dass das Modell tatsächlich den niedrigsten Punkt in der Landschaft gefunden hat! Es könnte sein, dass das Modell einfach in einem hohen Tal stecken geblieben ist. Die Metapher auflösend bedeutet dies, dass das Modell immer noch viele Fehler macht, aber keine Möglichkeit finden kann, genauer zu werden.
Außerdem wird es, selbst wenn das Modell tatsächlich den niedrigsten Punkt erreicht, noch lange dauern, bis es dort ankommt. Das liegt daran, dass das Modell alle Trainingsdaten immer und immer wieder ansehen muss, um zu bestimmen, welcher Weg nach unten führt.
Außerdem ist der Lernprozess jedes Mal anders. Das liegt daran, dass das Modell zufällig initialisiert wird (die anfänglichen Tests, die es verwendet, sind am Anfang zufällig). Es könnte also sein, dass du dein Modell trainierst und einen sehr niedrigen Punkt erreichst (das Modell hat hohe Genauigkeit). Aber wenn du dann die Trainingsdaten oder das Modell anpasst, erreichst du diesen niedrigen Punkt beim nächsten Trainingsdurchlauf möglicherweise nicht mehr.
Fazit: Nachteile von DL
Zusammenfassung der Nachteile von DL:
-
Du benötigst viele kuratierte und annotierte Trainingsdaten
-
Training braucht viel Zeit
-
Training ist nicht-deterministisch, d.h. es kann aus unbekannten Gründen fehlschlagen
Versteh mich nicht falsch: DL ist großartig und ich liebe es, es zu verwenden! Aber ich möchte dafür plädieren, DL nur in Fällen zu verwenden, in denen es tatsächlich erforderlich ist. Wenn eine einfachere Lösung möglich ist, sollte diese immer die erste Wahl sein.
Im nächsten Abschnitt möchte ich einen tatsächlichen Anwendungsfall beschreiben, bei dem wir bei LoyJoy eine anfängliche DL-Lösung durch einen viel agileren klassischen Computer-Vision-Ansatz (CV) ersetzt haben, wodurch viel Zeit und Mühe gespart wurden.
Problemdefinition
Hier bei LoyJoy bieten wir Treueprogramme für CPG-Marken (Consumer Packaged Goods) über Chatbots an. Verbraucher können einzigartige alphanumerische Codes für Belohnungen einlösen. Solche Codes (wie “74GH3D7E”) sind oft irgendwo außen oder innen auf der Verpackung aufgedruckt. Um die Einlösung für Verbraucher bequemer zu machen, erkennen wir auch Codes aus Bildern, die uns per Chat gesendet werden. Dieser Prozess macht das Leben des Verbrauchers wirklich einfach: Öffne unsere Progressive Web App, mache ein Foto und erhalte sofort deine Belohnung!

Bildunterschrift zum Testen (schwebendes Textbeispiel)
Beispiel für eine Oreo-Verpackung mit einem Treuecode außen.
Anfangs hatten wir eine komplexe DL-Lösung erstellt: Da wir nicht Zehntausende von Verpackungsbildern hatten, haben wir sie künstlich selbst generiert. Dann trainierten wir ein mehrschichtiges neuronales Netzwerk, das in der Lage war, alle Zeichen des Codes in einem Schritt zu erkennen. Grundsätzlich führte das Netzwerk Textfelderkennung, Zeichentrennung und Zeichenerkennung durch.
Während dieser Ansatz recht gut funktionierte, war die Zeit, die für die Generierung von Bildern und das Training des Netzwerks aufgewendet wurde, beträchtlich. Außerdem trainierte das Netzwerk manchmal überhaupt nicht, aus unbekannten Gründen.
Klassischer Computer-Vision-Ansatz
Bei einem klassischen CV-Ansatz können wir uns nicht auf ein Modell verlassen, das letztendlich alle Schritte lernt, die zur Erledigung der vorliegenden Aufgabe erforderlich sind. Stattdessen müssen wir bestimmen, welche Methoden wir in Verbindung verwenden können, um unser Ziel zu erreichen.
Für unser Projekt wollten wir zunächst einen Teil der DL-Pipeline ersetzen, nämlich die Textfelderkennung. Da die Position des Textfelds auf der Verpackung gleich bleibt, ist dies tatsächlich eine ziemlich einfache Aufgabe.
Wir brauchten einfach eine Methode, die die Positionen des Textfelds im Zielbild erkennen konnte, um es extrahieren zu können. In CV werden die Elemente eines Bildes Features genannt. Solche Features könnten harte Kanten mit starken Kontrasten sein, in unserem Fall zum Beispiel die Kanten des Textfelds. Es gibt zahlreiche Algorithmen zur Feature-Extraktion wie SURF, SIFT, BRIEF und AKAZE.
Mit diesen in einem Referenzbild des Textfelds und unserem Zielbild erkannten Kanten können wir die Features zwischen den beiden Bildern abgleichen und das Zielbild am Referenzbild ausrichten. Dieser Abgleich kann über FLANN oder Brute Force erreicht werden.

Beispiel für abgeglichene Features zwischen Ziel- und Referenzbildern. Features werden als blaue Kreise dargestellt, grüne Linien zeigen abgeglichene Features an.
Nach dem Abgleichen der Features können wir die Homographie zwischen der Position der Features in den beiden Bildern finden. Dies gibt uns im Grunde eine Matrix, die beschreibt, wie wir das Zielbild transformieren (drehen und verzerren) müssen, um das Textfeld an derselben Position wie im Referenzbild zu lokalisieren.
Nachdem wir die Transformation des Zielbilds durchgeführt haben, können wir einfach das Textfeld extrahieren und mit dem Schritt der optischen Zeichenerkennung fortfahren. Hier bei LoyJoy verwenden wir für diesen Schritt weiterhin ein DL-basiertes System.
Fazit: Vorteile von CV
Die Verwendung von CV für die Textfeldextraktion gibt uns in diesem Fall eine Reihe von Vorteilen:
-
Wir benötigen nur ein Referenzbild, um unser System an eine neue Verpackung anzupassen
-
Wir müssen keine Trainingsdaten generieren
-
Wir müssen unser Modell nicht neu trainieren
Wie du sehen kannst, macht uns das CV-Modell in diesem Fall das Leben deutlich einfacher. Bitte denke jedoch daran, dass dieser Fall nur ein Beispiel ist und dass ich nicht dafür plädieren möchte, nur klassisches CV die ganze Zeit zu verwenden.
Also, wann sollten wir klassisches CV anstelle von DL verwenden? Wie ich sagte, würde ich CV verwenden, solange die Aufgabe nicht zu komplex ist, um mit CV gelöst zu werden. Wenn du beispielsweise dasselbe Symbol in vielen verschiedenen Bildern ähnlichen Typs erkennen möchtest, kann dies einfach über klassisches CV erfolgen.
Andererseits ist DL wahrscheinlich der richtige Weg, wenn du verschiedene Arten von Objekten in allen Arten von Bildern erkennen möchtest. Dies ist in der ImageNet Large Scale Visual Recognition Challenge (einem der wichtigsten CV-Wettbewerbe) zu sehen, wo zunehmend tiefe neuronale Netzwerke die Gewinnerlisten dominieren.
Am Ende gibt es keine offensichtliche Lösung für das Problem. Du musst deinen Instinkten folgen und einfach verschiedene Lösungen ausprobieren. Wenn du jedoch vermutest, dass dein Problem mit klassischem CV gelöst werden könnte, ist es immer eine gute Idee, es zu versuchen - die Implementierung einer klassischen CV-Lösung ist wahrscheinlich schneller als das Training deines DL-Modells.